Telemetría
En esta sección hablaremos sobre las técnicas que aplicamos para capturar información de nuestras aplicaciones que nos permita medir el desempeño del sistema, monitorizar errores, o incluso auditar acciones de los usuarios. En esencia, este sistema de comunicación es lo que denominamos como telemetría y nos permite actuar principalmente de manera preventiva a futuros problemas, o de forma organizada y transparente ante eventos que debamos revisar.
¿Cómo logramos esto?
Para lograr esto tenemos que cumplir tres condiciones:
- Principalmente el sistema tiene que ser externo a nuestra aplicación. Esto lo necesitamos para garantizar independencia entre los sistemas y que el fallo de nuestras apps no afecte el acceso a los datos que tengamos. También facilita la escalabilidad de ambas partes y nos asegura que el performance de nuestros sistema no se vea afectado por el rendimiento de la telemetría.
- Debemos tener almacenamientos persistentes de todos los datos que decidamos registrar sobre nuestro sistema. Acá tenemos que tomar en cuenta que existen dos categorías de datos: Datos a nivel de aplicación, como logs y traces, y datos a nivel de infraestructura, como uso del CPU, la memoria y el disco.
- Nuestra solución debe presentar un Dashboard donde podamos ver las estadísticas de nuestros datos, así como mecanismos para que el departamento de Dev-Ops pueda auditar cualquier historial del sistema.
Todas estas condiciones las podemos cumplir con un grupo de herramientas ya existentes: Grafana, Loki, Pino y Prometheus. Veamos en detalle para que sirve cada una y como encajan en nuestra solución.
Ecosistema de Grafana
En principio necesitamos una manera de guardar toda la información que generemos, para esto existe un SaaS muy útil llamado Grafana. Éste provee varias herramientas tanto para preservar la información, como para visualizarla. Dentro del ecosistema de Grafana existen muchos productos, uno en particular llamado Loki es utilizado para mantener una base de datos de todos los logs que generemos, así que lo estaremos implementando junto con el dashboard.

Pino
Hasta ahora ya tenemos el visualizador y la base de datos de logs, por lo tanto nos toca solucionar el cómo enviaremos los logs a Loki. Aquí hablaremos del registrador Pino, que nos entrega una serie de librerías, entre las cuales tenemos pino-loki justamente para tratar este tema de una manera eficiente.

Pino nos permite ajustar la manera en que nos comunicamos con Loki, pero esto lo dejaremos para la sección de implementación.
Prometheus
Con los logs solucionados, ya tenemos una gran parte del sistema bajo vigilancia, pero todavía podemos agregar unas últimas métricas relacionadas con el servidor. En este punto utilizaremos una herramienta llamada Prometheus y su librería prom-client. Prometheus nos entrega un servicio para almacenar métricas del sistema en una base de datos a la cual se puede acceder a través de un lenguaje llamado PromQL, este servicio está alojado en una instancia de AWS, pero los detalles al respecto los dejaremos nuevamente para la sección de implementación.
Una vez tengamos nuestro servicio con la base de datos, podemos conectarlo con Grafana para desplegar esta información en un dashboard.

Arquitectura final
Juntando todas las piezas que hemos mencionado, quedaríamos con una arquitectura que nos permita registrar logs de nuestro sistema junto con métricas del servidor como su uso de CPU y memoria, mientras tenemos un dashboard alimentándose de ambas fuentes de información. A continuación se puede ver un diagrama resumen del sistema:
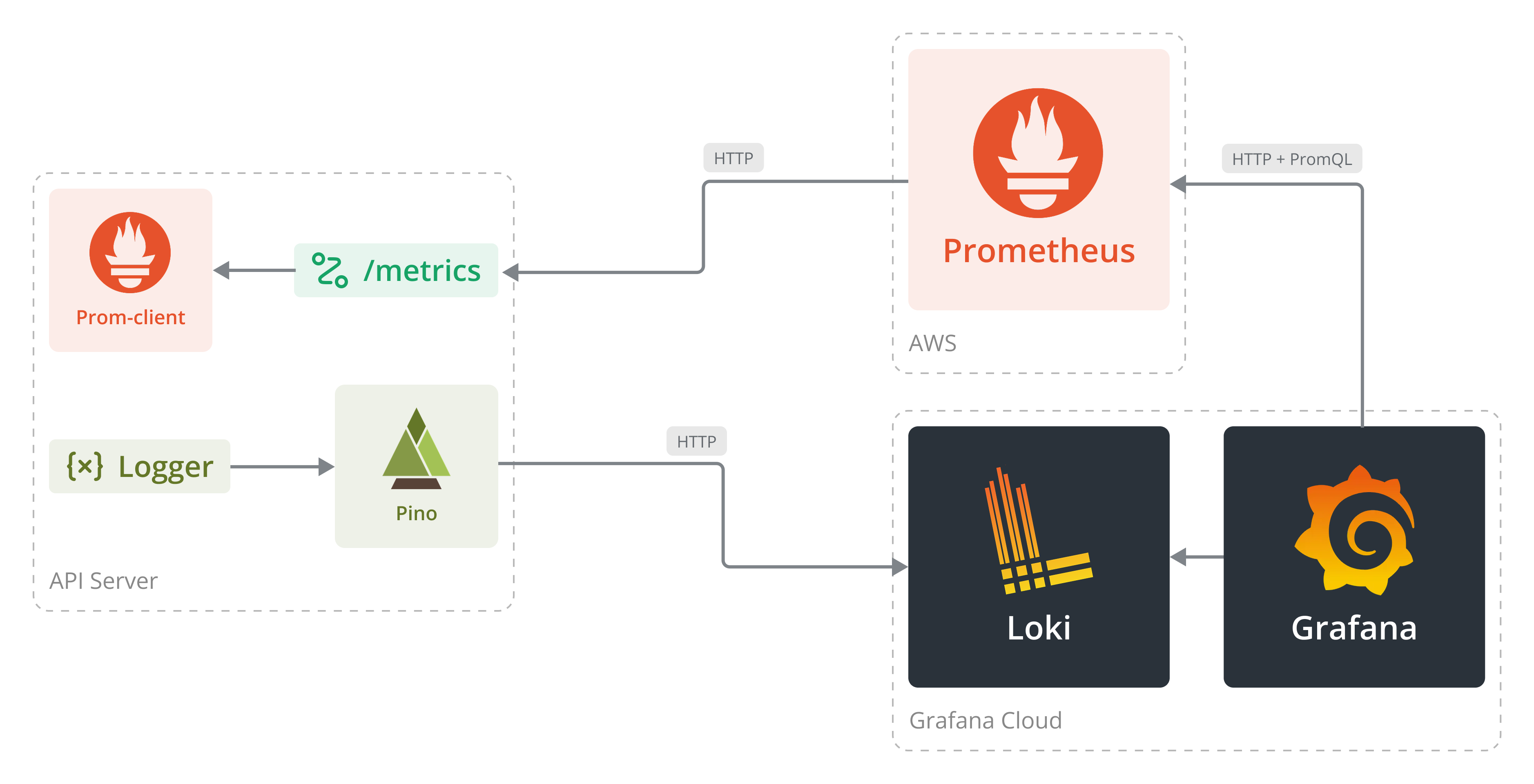
Revisando nuestras condiciones iniciales, podemos validar que:
- ✅ La solución es externa a nuestro sistema.
- ✅ Registra la información recibida de manera persistente.
- ✅ Contiene dashboards y métodos para acceder a la información.